
Die Semantischen Suchmaschinen befinden sich heute in allen für das Sourcing wichtigen Portale (z.B. XING, Linkedin, Google) im Einsatz – es gibt dort keine Keyword Suchmaschinen mehr. Diese Semantischen Suchmaschinen sind extrem komplexe Programme, sogenannte Algorithmen. Wer also gezielt suchen und finden möchte, muss sich mit den Funktionsweisen dieser algorithmischen Maschinen auseinandersetzen. Doch diese Maschinen sind keinesfalls universell einsetzbar und haben viele Limitationen. Wir erklären in diesem Blogpost die wichtigsten 8 Hindernisse von Semantischen Suchmaschinen, die jeder Sourcer (er-)kennen sollte.
Inhaltsverzeichnis
- Wie funktioniert ein (Such-)Algorithmus?
- Das Grundprinzip von Semantischen Suchmaschinen
- Die Funktionsweise von Semantischen Suchmaschinen
- Das Problem mit der Ergebnis-Anzeige
- Active Sourcing ist heute ein Hindernislauf
- Wie geht Sourcing Erfolg in Semantischen Suchmaschinen?
- Die Hindernisse von Semantischen Suchmaschinen für Sourcer
- Die Hitparade der 8 wichtigsten Hindernisse
- HINDERNIS NR. 8: Technische Eingriffe
- HINDERNIS NR. 7: Indexierung
- HINDERNIS NR. 6: Englische Sprache / Taxonomien
- HINDERNIS NR. 5: Anzeige / Ranking
- HINDERNIS NR. 4: (Persönliches) Netzwerk
- HINDERNIS NR. 3: “Intelligenz” des Algorithmus
- HINDERNIS NR. 2: Falsch-Positive Ergebnisse
- HINDERNIS NR. 1: Echoräume
- Fazit
- LEARNING
- Author
Wie funktioniert ein (Such-)Algorithmus?
Die Nutzung von Algorithmen ist wie das Autofahren: Wer nicht weiß, ob er ein Diesel-, Benzin- oder Elektroauto fährt, macht schnell beim Tanken oder im Service Fehler. Und bleibt liegen oder hat sogar einen Unfall. Im Grunde sind alle Algorithmen Spurensucher – sie suchen nach den Daten(-spuren), für die sie programmiert wurden und sind in der Lage eine Unzahl Informationen bis hin zu Big Data zu verarbeiten. Allerdings können sie nur diese Daten finden und auswerten, für die sie programmiert wurden. Und das sind niemals alle, die existieren!
So können Sie mit Google nicht das ganze Web durchsuchen (nur ca. 5 % des Webs – hier mehr). Denn ein (Such-)Algorithmus führt eine Vielzahl komplexer “wenn-dann”-Befehlsfolgen aus. Solche Sequenzen laufen eben wie Maschinen ab und schränken ein, weil sie Bedingungen vorgeben. Sourcer greifen durch ihre Suchanfrage in diese Befehlsausführung ein und versuchen den Algorithmus umzusteuern – das können sie nur dort, wo sich die Maschine umsteuern und beeinflussen läßt.
Das Grundprinzip von Semantischen Suchmaschinen
Sourcer müssen sich mit diesen aktuellen Semantischen Suchmaschinen beschäftigen. Die Semantischen Suchmaschinen haben das Ziel, nicht das Gleiche zu suchen wie Keyword Suchmaschinen. Sondern Semantische Suchmaschinen haben das Ziel, zu verstehen was die Keyword Kombination des Users bedeuten und dann das anzuzeigen, was er sucht. Besser formuliert: Etwas möglichst “Ähnliches” zu finden, zu dem was die Suchmaschine verstanden hat, dass der User sucht. Es geht nicht um die Eingabe eines Wortes, sondern um die Wortkombinationen und die Ähnlichkeit zu diesen Kombinationen.
Das Grundprinzip von Semantischen Suchmaschinen ist nach etwas Ähnlichem und nicht etwas Gleichem zu suchen!
Die Funktionsweise von Semantischen Suchmaschinen
Bezogen auf eine Keyword Kombination kann man die Funktionsweise von Semantischen Suchmaschinen aus Sicht der Sourcer – sehr verkürzt – so erklären: Sie
– berechnen ETWAS ÄHNLICHES UND
– führen eine AUTOKORREKTUR durch.
Je nach Programmierung werden diese in unterschiedlicher Reihenfolge und Ausprägung durchgeführt. Mal findet fast keine Autokorrektur statt, mal überlagert diese alles. Die schlechte Nachricht ist: Die Autokorrektur wird in Social Media Portalen nicht als solche angezeigt, aber findet dort auch statt. Sie ist positiv dort, wo Schreibfehler korrigiert werden. Sie kann aber auch den ganzen Sourcing Prozess zum Erliegen bringen (siehe Hindernis Nr. 1: Echoraum).
Beispiel in Google:
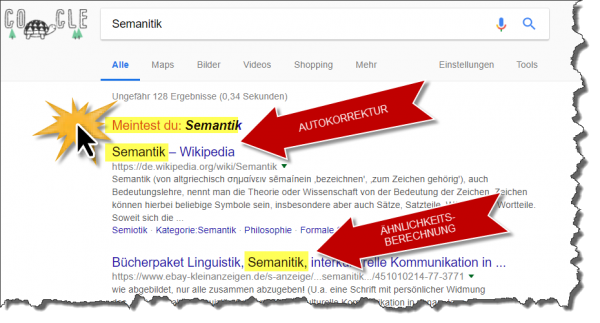
Das Problem mit der Ergebnis-Anzeige
Besonders wichtig ist für Sourcer die Anzeige: Sie bekommen selten das, was eine Semantische Suchmaschine “errechnet” direkt angezeigt. Die Anzeige der Ergebnisliste ist nicht universell gleich! Sie wird vom Algorithmus miterrechnet und autokorrigiert. Sie basiert in der Regel auf der Account-Version, die Sie einsetzen: Wer zum Beispiel in LinkedIn einen Freemium Account besitzt, sieht dort nur die Profil-Namen seines Netzwerkes der ersten und zweiten Kontakte. Nur im LinkedIn Recruiter sieht man alle Profilinformationen, auch die außerhalb des Netzwerkes.
Active Sourcing ist heute ein Hindernislauf
Suchmaschinen-Algorithmen sind also weit von perfekt. Der Traum der Sourcer, eine hellsehende Suchmaschine, wie die Werbung für Alexa, einzusetzen und diese dann noch in die Keywordsuche zwingen zu können, ist augenblicklich noch in weiter Ferne.
Aufgrund dieser Unzulänglichkeiten der Semantischen Suchmaschinen ist es nur möglich, mit Systematik, Disziplin und Logik zu suchen, wenn man gezielt und auch effizient Talente finden will.
Beim Active Sourcing werden Ungenauigkeiten und der Einsatz von Intuition oder Gefühl genauso wie Unkenntnis der Einschränkungen und Funktionsweisen der Tools bestraft. Diese Strafe sieht man nicht direkt: Man findet eindeutig weniger oder gar keine guten und passenden Kandidaten im Vergleich zu Sourcern, die wissen, wie man die Hindernisse vermeidet und die Auswahl haben.
Wie geht Sourcing Erfolg in Semantischen Suchmaschinen?
Es ist Unsinn, zu hoffen, dass eine algorithmische Suchmaschine selbstständig ein Talent über ein paar eingegebene Keywords identifizieren kann. Das Identifizieren und Matching muss immer noch der Sourcer selbst durchführen. Und das kann er definitiv erst, wenn er die Profile gefunden hat und checkt. Wenn er sie aber durch Hindernisse gar nicht erst findet, limitiert er sich selbst.
Sourcing ist nicht Suchen und Finden, sondern ist Suchen + Finden + Identifizieren + Matching und individuell Kontaktieren + Kommunizieren GLEICHZEITIG. Das geht nur, wenn man die PASSENDEN Informationen überhaupt findet.
Der Sourcing Erfolg hängt also definitiv auch davon ab, wie professionell man im Sourcing Prozess, das Vermeiden von Hindernissen und Lösen von Problemen einbaut. Steckt man erst mal in einer dieser Hindernis-Sackgassen, ist nicht selten die Lösung schwer – oder manches Mal sogar nicht mehr möglich. Denn je nach Ausprägung der Hindernisse, kann es sein, man sich sich selbst eine Grube gegraben hat, aus der es kein Entkommen gibt. Die Limitationen sollte man als Sourcer nicht unterschätzen, denn sie werden stetig mehr – durch immer mehr Sourcer.
Die Hindernisse von Semantischen Suchmaschinen für Sourcer
Die schlechte Nachricht ist: Es gibt weit über 20 Hindernisse Semantischer Suchmaschinen, die die Ergebnisse verzerren können.
———————————————————————————————
Wenn Sie diese alle erkennen und vermeiden lernen möchten, empfehlen wir Ihnen unseren
PRAXIS WORKSHOP ACTIVE SOURCING FÜR FORTGESCHRITTENE
– HIER auf der Website der Intercessio Academy finden Sie mehr Infos und Termine.
———————————————————————————————
Die gute Nachricht ist: Damit Sie heute schon erfolgreicher sourcen können, haben wir Ihnen unsere Hindernis-Hitparade erstellt. Diese Auswahl kann in allen gängigen Suchmaschinen (XING, LinkedIn, Google) sowie ebenso in den Prämientools (TalentManager oder Recruiter) auftauchen – in unterschiedlicher Ausprägung.
Die Hitparade der 8 wichtigsten Hindernisse
Hier sind sie also in umgekehrter Reihenfolge:
HINDERNIS NR. 8: Technische Eingriffe
Wenn ein Semantischer Algorithmus seine Berechnungen durchführt, dann greift er einerseits auf die Variablen zu, die festlegen, wie er die Informationen verarbeitet. Wieviele Variablen zum Beispiel Google hat und welche das genau sind bzw. in welcher Ausprägung diese arbeiten, ist eines der bestgehütesten Geheimnisse der Welt. Da aber Semantische Suchmaschinen auch zusätzlich konstant weiterentwickelt werden (man spricht bei Google z.B. von ca. 1000 technischen Eingriffen pro Jahr pro Sprache/Land), bleibt das System nie stehen. Aber wie alle digitalen Tools ist die Weiterentwicklung nicht linear und kann Disruptionen enthalten.
Es muss also jeder damit rechnen, dass auch bei XING und LinkedIn stille Änderungen durchgeführt werden, die nicht offiziell angekündigt werden. Zum Beispiel hat im Januar 2018 LinkedIn für die deutsche Sprache ein Update des Algorithmus für alle Accounts vorgenommen. Im Recruiter wirken nun die Booleschen Befehle überraschend gut (was vorher nicht so war), während der Einsatz dieser Keyword-Verbindungen genau umgekehrt im Business Account und Fremium Account massiv eingeschränkt wurde.
HINDERNIS NR. 7: Indexierung
Eine Suchmaschine besteht im Grunde nicht aus einem einzelnen Algorithmus, sondern aus zweien: Ein Algorithmus, der festlegt, welche Dateninformationen wie verarbeitet werden und den Content (=Inhalte = Datenkombinationen) indexiert. Dazu bewertet er Inhalte, z.B. ist das bei Google der sogenannte Crawler oder auch Google-Bot, der unter anderem festlegt, welche Websites überhaupt in den Google-Index übernommen werden. Und es gibt den zweiten Algorithmus, der mit dem ersten engverbunden ist, der die Suchanfrage bearbeitet und anzeigt. Diesen steuern wir als Sourcer durch unsere Eingabe von Keyword-Boolesche-Befehls-Kombinationen via Suchmaske
Aber: Google durchsucht nicht das ganze Web. Auch werden nicht alle XING-Profile/Seiten bei jeder Suchanfrage durchsucht und dito bei LinkedIn. Inhalte wie z.B. die Sprachkenntnisse bei LinkedIn werden nicht indexiert, aber stehen im Verzeichnis für die Suchanfrage zur Verfügung. Das heißt: Man kann sie nicht finden, obwohl man theoretisch danach suchen kann. Sie werden einfach nicht angezeigt. Diese Regel gilt für alle semantischen Algorithmen: Man kann nur das finden, wofür sie programmiert wurden.
HINDERNIS NR. 6: Englische Sprache / Taxonomien
Alle Semantische Suchmaschinen wurden zuerst einmal für eine bestimmte Sprache geschrieben: Das ist meist bei uns die englische Sprache. Damit haben wir schonper se ein Übersetzungsproblem, denn in den meisten Suchanfragen haben wir Deutsch und Englisch gemischt oder benützen unser DEnglisch (z.B. “Managerin” oder “Softwareentwickler” ). Mit einem Mischsprachsystem kann ein Algorithmus nicht ohne Ergänzung und Anpassung umgehen. Damit er Ähnlichkeiten berechnen kann oder die Indexierung passend vornimmt, muss man ihm Wortfamilien beibringen, sogenannte Taxonomien. Diese sind meist nur in Englisch vorgegeben, werden dann wie in in XING durch Deutsche Begriffe ergänzt. DEnglisch fällt häufig durchs Raster.
So findet Linkedin einen “Software Programmer” problemlos, aber hat seine Probleme mit einem “Programmierer”. XING ist am besten für die deutsche Sprache angepasst worden, aber nicht selten kann man erkennen: es kann mit DEnglischen Begriffen einfach nicht umgehen und zwar weil er sie nicht zuordnen kann. Die herausragende Intelligenz eines Semantischen Algorithmus wie Google oder Search! von Textkernel basiert zu einem erheblichen Teil nicht alleine auf den Berechnungsvariablen, sondern auf den klugen, durchdachten und an die Sprachen angepassten hinterlegten Taxonomien.
HINDERNIS NR. 5: Anzeige / Ranking
Wir sind so an Googles Ergebnisse gewöhnt, dass die meisten davon ausgehen, dass alle Algorithmen, die besten Ergebnisse zuerst anzeigen. Das ist aber nicht so, sondern nur Google rankt! Google versucht tatsächlich, dass ähnlichste Ergebnis zuerst anzuzeigen und es dann zu staffeln. “Versucht” ist das richtige Wort, denn das gelingt aufgrund der Einschränkungen nur bedingt.
Das heißt, zwar versuchen alle Semantischen Suchmaschinen, möglichst ähnliche Ergebnisse anzuzeigen. Aber die meisten haben das Ziel, eine gute Auswahl zu bieten – auch wenn man mit den “Ähnlichsten” als Gruppe beginnt – und die weniger passenden auf den folgenden Seiten gestaffelt anzeigt. In XING und Linkedin geht es nicht um ein Ranking der besten Kandidaten in der Anzeige, deshalb sollte man sich auch nicht auf die ersten Seiten beschränken.
HINDERNIS NR. 4: (Persönliches) Netzwerk
Sie als Sourcer haben es bestimmt schon bemerkt: Ihr eigenes Netzwerk wird in die Ergebnisliste überall miteinberechnet. Tendenziell zeigen Ihnen XING und LinkedIn unter ersten Ergebnissen die Kontakte ersten Grades und zweiten Grades gestaffelt an. Aber das ist nicht linear, denn der Algorithmus kann weitere Punkte wie z.B. ähnliche Profile, die sie in letzter Zeit geklickt wurden, einberechnen und anzeigen. Zum Beispiel wenn Sie erst intensiv Controller suchten und dann sich um Ihr Developer Projekt kümmern, können plötzlich auch Controllerprofile in der Ergebnisanzeige der Developer auftauchen.
Die Ursache ist einfach: Ein soziales Netzwerk möchte, dass Menschen mit gemeinsamen Interessen netzwerken. Und Sie haben durch intensive Suche gezeigt, dass Sie mit Controllern “matchen”. So erinnert der Algorithmus Sie in der Ergebnisanzeige daran. Das Problem existiert z.B. für spezialisierte Sourcer: Wenn Sie bei SAP arbeiten und SAP-Consultants suchen, dann sind Sie faktisch immer in diesem Netzwerk gefangen und müssen schon per se mindestens auf die Seite 10 in der Ergebnisliste suchen (wenn Sie überhaupt so viel Ergebnisse angezeigt bekommen). Das ist leider nicht auszuschalten, außer durch ein illegales zweites Profil (ABER: Zweitprofile sind in keinem für das Sourcing relevanten Social Media Portale in den AGB erlaubt, da sie Fakeprofile sind!!).
HINDERNIS NR. 3: “Intelligenz” des Algorithmus
Die Grundfrage, wie ein Algorithmus lernt, hängt von seinen Variablen, seiner Taxonomie und seiner Intelligenz, das heißt seiner Fähigkeit “Ähnlichkeit zu errechnen und zu erlernen” ab. Wir wissen nicht, wieviele Variablen Semantische Algorithmen haben (auch ändert sich das – siehe Hindernis 8). Aber wir können bezogen auf einzelnen Zielrichtungen Verhaltensweisen in der Ergebnisanzeige erkennen, wenn wir diese systematisch testen. Es gibt SEO Experten, die durch systematische Tests genau herausgefunden haben, wie bestimmte Variablen in Google, Twitter oder Facebook wirken.
Sourcer können das bezogen auf ihre Suchen ebenso und sollten das auch unbedingt. Um zu erkennen, wie ein Algorithmus lernt und funktioniert, sollte jeder Sourcer zuerst einmal bezogen auf seine Keyword Kombinationen den Algorithmus TESTEN und VOR DER SUCHANFRAGE herausfinden, wie der Algorithmus auf seine geplanten Keyword Kombinationen reagiert. Es macht ja keinen Sinn eine Suchanfrage mit ellenlangen Strings auf gut Glück zu schreiben – niemand kann einen Semantischen Algorithmus in die Keywordsuche zwingen.
HINDERNIS NR. 2: Falsch-Positive Ergebnisse
Auch das ist leider nichts Neues für erfahrenere Sourcer: In der Ergebnisanzeige der Suche nach Developern tauchen auch Recruiter Kollegen auf, die diese Keywords auf ihrem Profil haben – oder die in letzter Zeit solche Developer Profile gesucht bzw. angeklickt haben (siehe Hindernis 4: Netzwerken). Man nennt diese Anzeige ein falsch-positives Ergebnis.
Man kann versuchen dieses Hindernis zu vermeiden, indem man systematisch diese Anzeige falsch-positiver Ergebnisse ausschließt. Wenn Sie also Recruiter-Kollegen angezeigt bekommen, können Sie durch Minusbefehl z.B. -Recruiter versuchen, diese Profile auszuschließen. Aber Achtung: Erstens funktioniert ein zweiter Minusbefehl aus technischen Gründen in der XING Erweiterten Suche nicht (also z.B. -Recruiter -Personalberater geht nicht). Und zweitens greift auch hier hin und wieder die Autokorrektur in Zusammenhang mit dem Hindernis 4: Netzwerken und ignoriert ihre Eingabe in der Erweiterten Suche von XING (nicht im XING TalentManager!).

HINDERNIS NR. 1: Echoräume
Verkürzt erklärt: Sie bekommen durch die Selektion des Algorithmus und seiner Autokorrektur manches Mal nur das angezeigt, was andere geklickt oder gesucht haben. Dieses Phänomen nennt man einen ECHORAUM. Sie kennen das von Amazon’s Semantischem Algorithmus: “Kunden, die kauften, kauften auch”. Sie sehen also in einem Echoraum in XING Ergebnisse, die andere Recruiter oder Sourcer geklickt haben. In LinkedIn ist das schlimmer, der Algorithmus ist intelligenter. Er rechnet auch in die Ergebnisse und die Autokorrektur ein, was anderen angezeigt wurde (wie in Amazon, Zalando, Trivago und den meisten Shopsystemen). Der Echoraum ist also – in kurz – ein Ergebnis der Autokorrektur.
Echoräume tauchen immer dort auf, wo Algorithmen auch Menschenbeziehungen in die Ergebnisse einrechnen. Und wie wir wissen, tun das Semantische Suchmaschinen. Im Grunde sind sie die Umkehrung der FILTERBLASE (hier ein Video dazu). Die Filterblase des Facebook Algorithmus zeigt dem User nur das an, was dem entspricht, was er gelikt und gelesen hat, und das was seine engsten und mit ihm im aktivsten Austausch befindlichen Freunde teilen.
Echoräume gibt es überall, also auch in XING, LinkedIn und Google – und man kann sie nicht abschalten! Aber man kann sie – meistens – umgehen, wenn man, sie erkennt. Meine Schätzung ist, dass wir bereits durch die aktive Nutzung durch Active Sourcer in manchen Berufsgruppen wie z.B. Expertensuchen für die Softwareentwickung 40-50 % in Echoräumen landen. Wer diese nicht erkennt, schreibt immer genau die Leute an, die an diesem Tag/Woche/Monat schon von zig anderen Sourcern kontaktiert wurden …
Fazit
Es ist heute nicht mehr möglich, effizient zu sourcen, ohne die Unzulänglichkeiten und Hindernisse der Algorithmen einzuplanen. Dies geht nur, in dem wir den Sourcing Prozess systematisch konzipieren und die Umsetzung konsequent und nachhaltig logisch durchführen. (Mehr zum effizienten Sourcing Prozess hier im Blogartikel: Wie läuft der professionelle, erfolgreiche Active Sourcing Prozess ab?
LEARNING
Die digitalen Medien/Sources und Tools sind nur so gut wie der User, der sie benützt. Neben Systematik sollte ein professioneller Sourcer deshalb auch die Funktionsweisen der Tools und Medien und ihre Limitationen kennen und beherrschen lernen. Er sollte sich die Existenz der Hindernisse unbedingt bewußt macht, damit er diese vermeidet, Zeit spart und gezielter bessere Talente finden kann.
HAPPY SOURCING!



Hinterlassen Sie einen Kommentar